Morning Stella outage
Update: I posted a follow-up on this outage.
Stella was down for about an hour and a half this morning, including checkups and monitors. I received a notification at 9am (PST) and the site returned to normal at 10:40am. Here is a screenshot of status.blamestella.com form this morning:
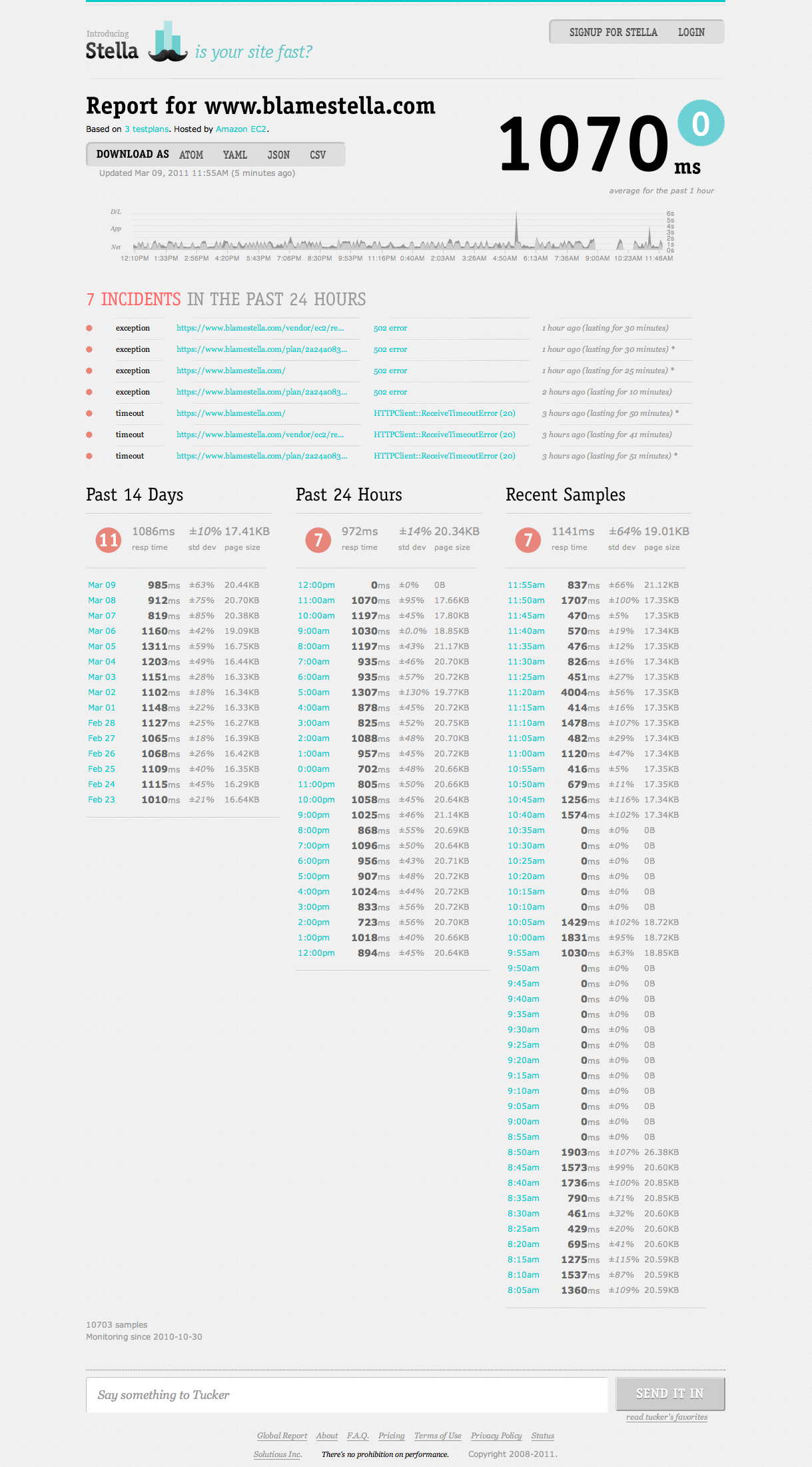
The symptoms
The web servers were not responding and the master backend machine was not available via SSH (I could connect but it would hang after authenticating). The connection to Redis was not affected.
The cause
I couldn’t verify that there was a single root cause. I couldn’t SSH in to the machine until after it was rebooted but it looks like something happened while Redis was running a background save. The only access I had was through redis-cli:
redis> bgsave
(error) ERR Background save already in progress
redis> save
(error) ERR Background save already in progress
redis> info
...
aof_enabled:0
changes_since_last_save:67162
bgsave_in_progress:1
used_memory_human:2.21G
mem_fragmentation_ratio:1.44
...
My thinking at the time was that the process was swapping to VM so I waited patiently (not so patiently actually) to see if it would finish. There’s 7.5GB of RAM and Redis was only using about 2.5GB so there shouldn’t have been a need to swap but it’s possible (I’ve noticed that the redis-server process has used as much as 1GB more than what it report via info). As you can see there was some data in memory that hadn’t been written to disk yet so that was my top priority (changes_since_last_save). After about 20 minutes it was clear that there was something else going on and my top priority switched to getting the site back up. The data is stored on an EBS volume so my guess is that there was degraded IO performance. To be clear, I don’t suspect it was an issue with Redis itself. However, that still doesn’t explain why I couldn’t login via SSH so it’s possible there was a network issue at the same time (which I’ve experienced before in other EC2 available zones).
At that point I made the decision to reboot the machine. I also started the process of provisioning a new backend machine using the most recent backup (which was created an hour earlier). I did these in parallel in the event that the existing machine did not come back up. It did and after it ran an fsck I was able to get into the machine. I brought redis up, tested it, and then started the workers (which do the monitoring). Then I brought up the site after a few minutes.
Note: in the report you can see that the site came up briefly at 10am (PST). This was before the backend machine was restarted. The web servers could read and write to Redis but the monitoring and checkups jobs were not running.
Next steps
- Switch to append-only backups to prevent the need for epic writes.
- Create and practice a new recovery process to provision a new machine right away which can run off of a snapshot of the master’s EBS volume.